

Hive的常见文件存储格式
在hive中,较常见的文件存储格式有:TextFile、SequenceFile、RcFile、ORC、Parquet、AVRO。默认的文件存储格式是TextFile。
RCFile、ORC、Parquet这三种格式,均为列式存储表。准确来说,应该是行、列存储相结合。

除TextFile外的其他格式的表不能直接从本地文件导入数据,数据要先导入到TextFile格式的表中,然后再从表中用insert导入到其他格式的表中。
TextFile格式
在建表时无需指定,Hive的默认文件格式,文件存储方式为正常的文本格式。以TextFile文件格式存储的表,在HDFS上可直接查看到数据。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但是使用这种方式,hive不会对数据进行切分,无法对数据进行并行操作。在TextFile表压缩后再进行解压,即反序列化时,耗费的时间很大,是SequenceFile的十几倍。
存储方式:行存储
优势:可使用任意的分割符进行分割;在hdfs上可查可标记;加载速度较快;
劣势:不会对数据进行压缩处理,存储空间较大、磁盘开销大、数据解析开销大。
使用场景:作为外部数据导入存储,或者导出到外部数据库的中转表。可以识别在hdfs上的普通文件格式(如txt、csv),因此该模式常用于仓库数据接入和导出层;
SequenceFile格式
需在建表是指定stored as sequecefile,文件存储方式为二进制文件,以<key,value>的形式序列话到文件中。以SequenceFile文件格式存储的表,会对数据进行压缩处理,在HDFS上的数据为二进制格式,不可直接查看。
可以把SequenceFile当做是一个容器,把所有的文件打包到SequenceFile类中可以高效的对小文件进行存储和处理。SequenceFile文件并不按照其存储的Key进行排序存储,SequenceFile的内部类Writer提供了append功能。
在存储结构上,SequenceFile主要由一个Header后跟多条Record组成,Header主要包含了Key classname,value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。每条Record以键值对的方式进行存储,用来表示它的字符数组可以一次解析成:记录的长度、Key的长度、Key值和value值,并且Value值的结构取决于该记录是否被压缩。
可与record、none、block(块级别压缩)配合使用,默认为record,但record的压缩率低,一般建议使用block压缩,压缩率最高的是Block。
三种类型的压缩:
A.无压缩类型:
如果没有启用压缩(默认设置)那么每个记录就由它的记录长度(字节数)、键的长度,键和值组成。长度字段为4字节。 B.记录压缩类型:
记录压缩格式与无压缩格式基本相同,不同的是值字节是用定义在头部的编码器来压缩。注意:键是不压缩的。下图为记录压缩:
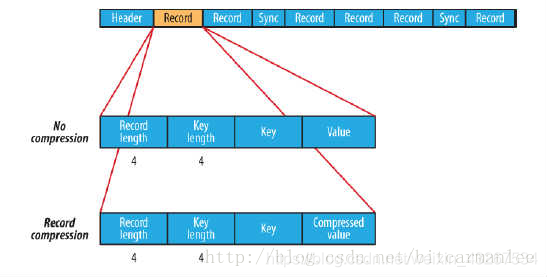
C.块压缩类型:
块压缩一次压缩多个记录,因此它比记录压缩更紧凑,而且一般优先选择。当记录的字节数达到最小大小,才会添加到块。该最小值由io.seqfile.compress.blocksize中的属性定义。默认值是1000000字节。格式为记录数、键长度、键、值长度、值。下图为块压缩:
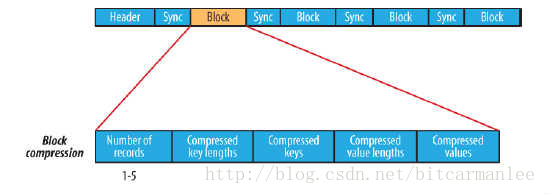
存储方式:行存储
优势:文件和Hadoop API的MapFile是相互兼容的;存储时候会对数据进行压缩处理,存储空间小;支持文件切割分片;查询速度比TextFile速度快;
劣势: 无法可视化展示数据;不可以直接使用load命令对数据进行加载;自身的压缩算法占用一定的空间;该种模式是在textfile基础上加了些其他信息,故该类格式的大小要大于textfile,现阶段基本上不用。
使用场景:如果在生产中,需要数据进行行式存储、原生支持压缩,且要满足一定的性能要求,那么可以使用SequenceFile这种存储方式
RcFile格式
需在建表是指定stored as rcfile,文件存储方式为二进制文件。以RcFile文件格式存储的表也会对数据进行压缩处理,在HDFS上以二进制格式存储,不可直接查看。
RCFILE是一种行列存储相结合的存储方式,该存储结构遵循的是“先水平划分,再垂直划分”的设计里面。首先,将数据按行分块形成行组,这样可以使同一行的数据在一个节点上。然后,把行组内的数据列式存储,将列维度的数据进行压缩,并提供了一种lazy解压技术。
Rcfile在进行数据读取时会顺序处理HDFS块中的每个行组,读取行组的元数据头部和给定查询需要的列,将其加载到内存中并进行解压,直到处理下一个行组。但是,rcfile不会解压所有的加载列,解压采用lazy解压技术,只有满足where条件的列才会被解压,减少了不必要的列解压。
在rcfile中每一个行组的大小是可变的,默认行组大小为4MB。行组变大可以提升数据的压缩效率,减少并发存储量,但是在读取数据时会占用更多的内存,可能影响查询效率和其他的并发查询。用户可根据具体机器和自身需要调整行组大小。
存储方式:行列混合的存储格式,将相近的行分块后,每块按列存储。
优势:基于列存储,压缩快且效率更高,;占用的磁盘存储空间小,读取记录时涉及的block少,IO小;查询列时,读取所需列只需读取列所在块的头部定义,读取速度快(在读取全量数据时,性能与Sequence没有明显区别);
劣势:无法可视化展示数据;导入数据时耗时较长;不能直接使用load命令对数据进行加载;自身的压缩算法占用一定空间,但比SequenceFile所占空间稍小;
使用场景:现在基本很少使用了,它是ORC表的前身,支持的功能和计算性能都低于ORC表。RCFile对于提升任务执行性能提升不大,但是能节省一些存储空间。
ORC格式
需在建表是指定stored as ORC,文件存储方式为二进制文件。ORC文件格式从hive0.11版本后提供,是RcFile格式的优化版,主要在压缩编码,查询性能方面做了优化。ORC具备一些高级特性,如:update操作,支持ACID,支持struct、array复杂类型。Hive1.x版本后支持事务和update操作,就是基于ORC实现的(目前其他存储格式暂不支持)。
存储方式:按行组分割整个表,行组内进行列式存储。 文件结构:
首先做一些名词注释:
ORC文件:保存在文件系统上的普通二进制文件,一个ORC文件中包含多个stripe,每个stripe包含多条记录,这些记录按照列进行独立存储。
文件级元数据:包括文件的描述信息postscript、文件meta信息(包括整个文件的统计信息)、所有的stripe的信息和schema信息。
Stripe:一组行形成一个stripe,每次读取文件是以行组为单位的,一般为hdfs的块大小,保存了每一列的索引和数据。
Stripe元数据:保存stripe的位置、每个列在该stripe的统计信息以及所有的stream类型和位置。
Row group:索引的最小单位,一个stripe中包含多个row group,默认为10000个值组成。
Stream:一个stream表示文件中的一段有效的数据,包括索引和数据。索引stream保存每一个row group的位置和统计信息,数据stream包括多种类型的数据,具体情况由该列类型和编码方式决定。
在ORC文件中保存了三个层级的统计信息,分别为文件级别、stripe级别和row group级别,他们可以根据下发的搜索参数判断是否可以跳过某些数据。在这些统计信息中包含成员数和是否有null值,且对不同类型的数据设置了特定统计信息。
ORC的文件结构如下:
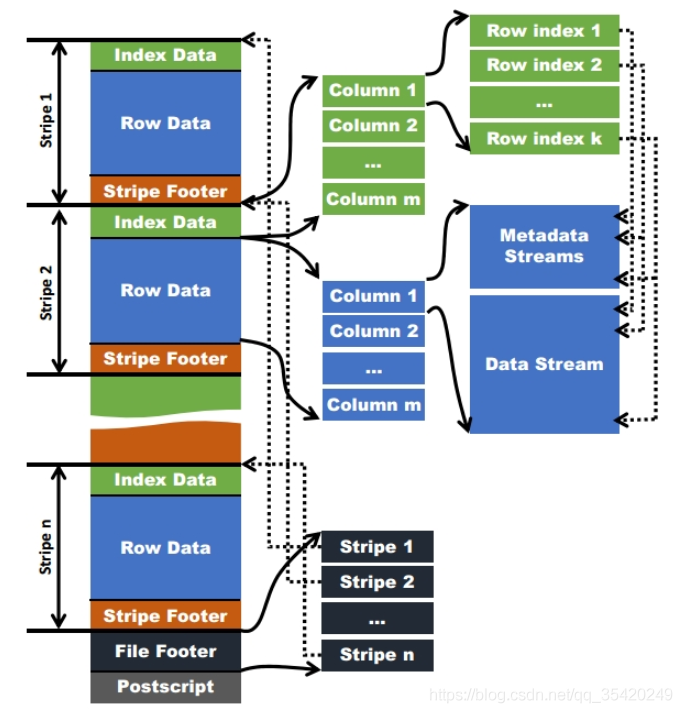
文件级别:
在ORC文件的末尾记录了文件级别的统计信息,包括整个文件的列统计信息。这些信息主要是用于查询的优化,也可以为一些简单的聚合查询如max、min、sum输出结果。
Stripe级别:
保留行级别的统计信息,用于判断该Stripe中的记录是否符合where中的条件,是否需要被读取。
Row group级别:
进一步避免读取不必要的数据,在逻辑上将一个column的index分割成多个index组(默认为10000,可配置)。以这些index记录为一个组,对数据进行统计。在查询时可根据组级别的统计信息过滤掉不必要的数据。
优势:支持NONE、Zlib、Snappy压缩, 具有很高的压缩比,且可切分;由于压缩比高,在查询时输入的数据量小,使用的task减少,所以提升了数据查询速度和处理性能;每个task只输出单个文件,减少了namenode的负载压力;在ORC文件中会对每一个字段建立一个轻量级的索引,如:row group index、bloom filter index等,可以用于where条件过滤;可使用load命令加载,但加载后select * from xx;无法读取数据;查询速度比rcfile快;支持复杂的数据类型;
劣势:无法可视化展示数据;读写时需要消耗额外的CPU资源用于压缩和解压缩,但消耗较少;对schema演化支持较差;
可通过命令查看ORC文件系统信息:
./hive –orcfiledump -j -p hdfs://cdh5/hivedata/warehouse2/lxw1234_orc2/000000_0
它是Hive特有的存储类型;所以在其它大数据产品中兼容性并不好,有些只有在较高的版本中才会支持。
使用场景: 在分析计算中的性能较好,是生产中常见的表类型。
Parquet格式
Apache Parquet是HadooApache Parquet是Hadoop生态圈中一种新型列式存储格式,它可以兼容Hadoop生态圈中大多数计算框架(Hadoop、Spark等),被多种查询引擎支持(Hive、Impala、Drill等),并且它是语言和平台无关的。Parquet最初是由Twitter和Cloudera(由于Impala的缘故)合作开发完成并开源,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
需在建表是指定stored as PARQUET,文件存储方式为二进制文件。Parquet基于dremel的数据模型和算法实现,只是一种存储格式,它与上层平台、语言无关,不需要与任何数据处理框架绑定,适配多种框架结构。
它的计算性能稍弱于ORC表;但因为Parquet文件是Hadoop通用的存储格式,所以对于其它大数据组件而言,具有非常好的数据兼容度;而且Parquet表可以支持数据的多重嵌套(如JSON的属性值可以是一个对象,且支持嵌套),但ORC表在多重嵌套上的性能并不好。
Parquet支持uncompressed、snappy、gzip、lzo压缩;
其中lzo压缩方式压缩的文件支持切片,意味着在单个文件较大的场景中,处理的并发度会更高;因为一个压缩文件在计算时,会运行一个Map任务进行处理,如果这个压缩文件较大,处理效率就会降低。
在HDFS文件系统和Parquet文件中存在如下几个概念。 HDFS块(Block):它是HDFS上的最小的副本单位,HDFS会把一个Block存储在本地的一个文件并且维护分散在不同的机器上的多个副本,通常情况下一个Block的大小为256M、512M等。
HDFS文件(File):一个HDFS的文件,包括数据和元数据,数据分散存储在多个Block中。
行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,Parquet读写的时候会将整个行组缓存在内存中,所以如果每一个行组的大小是由内存大的小决定的,例如记录占用空间比较小的Schema可以在每一个行组中存储更多的行。
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
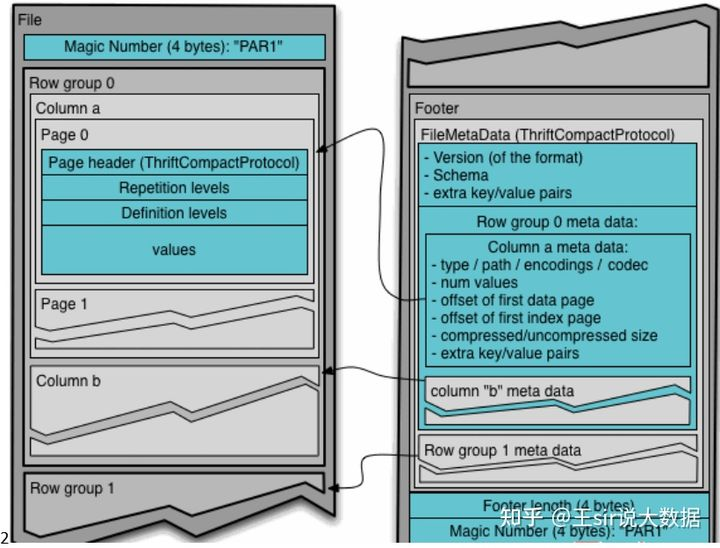
存储方式:列式存储
优势:具有高效压缩和编码,使用时有更少的IO取出所需数据,速度比ORC快;其他方面类似于ORC;
劣势:不支持update;不支持ACID;不支持可视化展示数据
使用场景:只在Hive中处理时使用,追求更高效的处理性能,且单个文件不是很大,或者需要有事务的支持,则选用ORC表。
但如果要考虑到与其它大数据产品的兼容度,且单个文件较为庞大,数据存在多重嵌套,则选用Parquet表。
AVRO
由Hadoop工作组于2009年发布的Apache Avro,是一种基于行的、可高度拆分的数据格式。Avro能够支持多种编程语言。通常,它也被描述为类似于Java序列化的数据序列化系统。为了最大程度地减小文件大小、并提高效率,它将schema存储为JSON格式,而将数据存储为二进制格式。
Avro通过管理各种添加、丢失、以及已更改的字段,来为schema的演化提供强大的支持。这使得旧的软件可以读取新的数据,而新的软件也可以读取那些旧的数据。而这对于那些经常发生变更的数据而言,是非常重要的。
Avro通过schema架构的管理能力,可以在不同的时段独立地更新不同的组件,从而降低了不兼容性所带来的风险。同时,开发人员既不必在应用程序中编写if-else语句,来应对不同的架构版本,也不必通过查看旧的代码,来理解那些旧的架构。而且,所有版本的schema都存储在可读的JSON标头中,以方便开发人员理解所有可用的字段。
如前文所述,由于schema是以JSON格式存储的,而数据是以二进制形式存储的,因此Avro是持久性数据存储和电传(wire transfer)的简约之选。另外,由于用户能够轻松地向Avro附加新的数据行,因此它通常是那些大量写入工作负载的首选格式。
它主要为 Hadoop 提供数据序列化和数据交换服务,支持二进制序列化方式。
因为AVRO是Hadoop生态圈中,常用的一种用于数据交换、序列化的数据类型,它与Thrift类似。但要与TextFile区分开来,TextFile文本方式是常见的存储类型,基本所有系统都支持;
但一般而言,在数据传输中,不会直接将文本发送出去,而是先要经过序列化,然后再进行网络传输,AVRO就是Hadoop中通用的序列化标准。
优点: Avro是一种与语言无关的数据序列化。 Avro将schema存储在文件的标题中,因此数据具有自描述性。 Avro格式的文件既可以被拆分、又可以被压缩,因此非常适合于在Hadoop生态系统中进行数据的存储。 由于Avro文件将负责读取的schema与负责写入的schema区分开来,因此它可以独立地添加新的字段。 与序列文件(Sequence Files)相同,为了实现高度可拆分性,Avro文件也包含了用于分隔不同块(block)的同步标记。 可以使用诸如snappy之类的压缩格式,来压缩不同的目标块。
使用场景:如果数据通过其他Hadoop组件使用AVRO方式传输而来,或者Hive中的数据需要便捷的传输到其他组件中,使用AVRO表是一种不错的选择。
总结:
Hive在生产中,一般使用较多的是TextFile、Orc、Parquet。
TextFile一般作为数据导入、导出时的中转表。
ORC和Parquet表一般作为分析运算的主要表类型,如果需要支持事务,则使用ORC,如果希望与其它组件兼容性更好,则使用Parquet。
在性能上ORC要略好于Parquet。但Parquet支持压缩切分,有时候也是考虑因素。
当然除了这几种内置表,Hive还支持自定义存储格式。可通过实现 InputFormat 和 OutputFormat 来完成。